Scenario¶
We configure our machines to be running the Xen hypervisor and a recent linux kernel as the dom0 controller. The scenario includes using Xen, ATA-over-Ethernet (AoE) layer on the private LAN, with each machine exporting unused partitions from their HDD’s to the AoE pool. We can then treat these AoE devices as LVM physical volumes, and assemble a cluster-wide shared volume group, available to the dom0 instances on both machines. Finally, we’ll extract logical volumes from this volume group, and create a RAID1 mirror across them with with mdadm. We can create Xen domUs with the RAID1 devices as their block devices.
We started at the Lair early saturday morning (like 10:30 am). We had three physical computers:
- squash, IBM Aptiva,
- pita: IBM Aptiva, PIII, 512 MB
- zorro: IBM Aptiva, PIII, 512 MB
We spent the first several hours getting all machines properly booting and installed with Debian. We then spent a lot of time installing things like Gobby and silc and getting everyone on the same virtual spaces (since being physically present wasn’t enough).
We assigned the following roles and software to each computer:
- squash, Debian Etch, monitor the other two servers
- pita, Debian Lenny, export hard drive space to the network
- zorro, Debian Lenny, export hard drive space to the network
"monitor"
+----------+ +----------+ +----------+
| | | P3 512MB | | P3 512MB |
| squash | | pita | | zorro |
+----------- +----------+ +----------+
| | | | | |
| | | | | |
+-----|---------------+-----|---------------+-----|---------> to LAN/WAN
| | |
+---------------------+---------------------+ (private LAN)
After much gnashing of teeth, we decided to setup the following architecture:
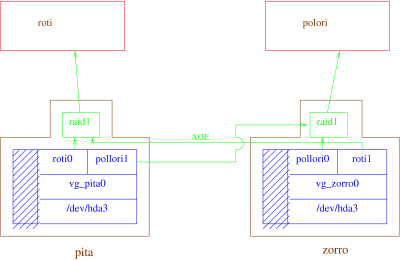
Rationale¶
In this scenario we manage the LVM for the underlying block devices on the Dom0’s themselves, handing off those componants to the DomUs who then manage their mdadm RAID.
We have N Dom0s, and K DomUs, where we assume that K > N.
Other architecture scenarios¶
Other scenarios we toyed with were bringing the RAID management down into the Dom0, and we actually ended up going with the Dom0 managing the RAID initially. It wasn’t exactly clear from the beginning which way would prove to be the preferable as each had its own advantages and disadvantages.
- Advantage of Dom0 managing RAID: rebuilds can be more easily coordinated within a dom0, if many devices are attempting to rebuild simultaneously.
- Advantage of DomU managing RAID: DomU migration should be smoother, as Dom0’s don’t need to know about handing off RAID management during the transfer.
Another model was to have all Dom0 block devices exported directly as PVs into a single, cluster-wide VG. The advantage of this would be ease of management from any of the Dom0s. Disadvantage is the cluster-LVM is apparently flakey.
Take a break¶
Since the architecture design, goals and possibilities were complicated and we had to do a lot of drawing on a whiteboard and talking about abstract ideas our heads were about to explode, so we had to take a break:
# aptitude install bb
# /usr/games/bb
After watching this and eating some roti, we were much better off.
Setup the Dom0 (the hosts)¶
We installed the following packages on pita and zorro:
- linux-image-2.6.18-5-xen-686
- xen-hypervisor-3.1-1-i386
Then we edited /boot/grub/menu.lst:
## The following ouputs grub to the serial console and should be added to the top
serial --unit=0 --speed=115200 --parity=no --stop=1
terminal serial
## Xen hypervisor options to use with the default Xen boot option
## setting the mem option limits the amount of RAM that the dom0 takes to only 128
# xenhopt=dom0_mem=131072 com1=115200,8n1
We then rebooted the machines to get the hypervisor running, so Dom0 was up.
We needed to get the Xen bridging configuration setup, to do that we commented out one line and added another:
codetitle. /etc/xen/xend-config.sxp
#(network-script network-dummy)
(network-script 'network-bridge netdev=wan')
Then restarted xend:
# /etc/init.d/xend restart
Logical Volume Management (LVM) setup¶
The following were run on both zorro and pita (only zorro being shown):
0 zorro:/usr/share/doc/aoetools# pvcreate /dev/hda
hda hda1 hda2 hda3
0 zorro:/usr/share/doc/aoetools# pvcreate /dev/hda3
Physical volume "/dev/hda3" successfully created
0 zorro:/usr/share/doc/aoetools# vgcreate vg_zorro0 /dev/hda3
Volume group "vg_zorro0" successfully created
0 zorro:/usr/share/doc/aoetools# vgs
VG #PV #LV #SN Attr VSize VFree
vg_zorro0 1 0 0 wz--n- 11.23G 11.23G
0 zorro:/usr/share/doc/aoetools# lvcreate -L3G -n roti0 vg_zorro0
Logical volume "roti0" created
0 zorro:/usr/share/doc/aoetools# lvcreate -L3G -n polori0 vg_zorro0
Logical volume "polori0" created
0 zorro:/usr/share/doc/aoetools# lvs
LV VG Attr LSize Origin Snap% Move Log Copy%
polori0 vg_zorro0 -wi-a- 3.00G
roti0 vg_zorro0 -wi-a- 3.00G
We wanted to do a little bit of LVM configuration because we didn’t want LVM to be probing the AOE devices when they come up because they could hang and block processes on discovery. We wanted to tell LVM to ignore /dev/ethered devices:
codetitle. /etc/lvm/lvm.conf
filter = [ "r|/dev/etherd/.*|" ]
Note: only one filter line is allowed.
Xen issues¶
the kernels of both dom0s report thousands of these messages:
pwan: received packet with own address as source address
It’s the same as upstream bug 339. It seems to be because the virtual network bridges created on each dom0 are both set to MAC address fe:ff:ff:ff:ff:ff, and both respond to ARP requests. Thus, each kernel on a shared network gets the ARP responses from the other kernel’s virtual bridge. In theory, this should be fixable by turning off ARP on every virtual NIC with that fake MAC address:
ip link set xenbr0 arp off
but that doesn’t seem to stop the messages, even if it’s done on every dom0 on the network.
ATA-over-Ethernet (AOE)¶
The Debian Administration pages had a good starter guide on AOE.
First we install the necessary packages (do this on both machines):
0 zorro:~# aptitude install vblade aoetools
Then we start up the vblade daemon, exporting the vg_zorro0-roti0 volume from zorro:
0 zorro:~# vblade 0 0 lan /dev/mapper/vg_zorro0-roti0
Then on pita we can see these devices over the network:
0 pita# aoe-discover
0 pita# aoe-stat
... output from aoe-stat should go here...
We were interested in knowing what was happening over the network, so we fired up tshark on the 17" VGA monitor attached to squash (which had no window manager running):
0 squash# rxvt-xterm -fn '-adobe-courier-medium-r-normal--34-240-100-100-m-200-iso8859-1' -bg black -fg green -cr red -geometry 62x35 -e tshark -i lan
Create the RAID¶
The first time we did this we created a mirrored raid in the Dom0 which consisted of one element of the RAID array coming from the AoE exported device from the second machine, and one local.
0 pita# mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/etherd/e0.0 /dev/mapper/vg_pita0-roti0
and then we created a ext3 filesystem on /dev/md0:
0 pita# mke2fs -t ext3 /dev/md0
We then fed this /dev/md0 to the DomU. We experimented with this for a while, but decided instead that the benefits of the DomU managing the raid inside were preferable than those managing it outside. See above in the section entitled, ‘Other architecture scenarios’ for the rationale.
DomU setup¶
Now that we have the underlying devices and a filesystem available, we wanted to get the Xen DomU called Roti setup. To do this, we mounted the new MD device on Pita, and then debootstrap on to it:
0 pita:~# aptitude install debootstrap
0 pita:~# mkdir /target
0 pita:~# mount /dev/md0 /target
0 pita:~# http_proxy=http://proxy.lair.fifthhorseman.net:3128/ debootstrap lenny /target
Within the new Roti debootstrap we needed to setup a few basic things:
- modified /etc/hostname, /etc/hosts, /etc/apt/sources.lst (point to both etch and lenny), /etc/network/interfaces
- installed mdadm and linux-modules-2.6.18-5-xen-686
- install libc6-xen
pita:/# cat /etc/fstab /dev/sda1 / ext3 defaults,errors=remount-ro 0 1 proc /proc proc defaults 0 0
Then we needed to setup the Roti Xen configuration:
codetitle. /etc/xen/roti
kernel = '/boot/vmlinuz-2.6.18-5-xen-686'
ramdisk = '/boot/initrd.img-2.6.18-5-xen-686'
memory = '238'
name = 'roti'
root = '/dev/sda1 ro'
dhcp = 'dhcp'
vif = [ '' ]
disk = [ 'phy:md0,sda1,w' ]
on_poweroff = 'destroy'
on_reboot = 'restart'
on_crash = 'restart'
Then create and start the DomU:
0 pita# xm create -c roti
Testing¶
We didn’t have much time left, so we only managed to describe two tests and run one.
Migration/Transition scenario¶
The idea behind this scenario is we need to migrate a DomU from one machine to another, with as little downtime as possible. The idea is to be able to enact a live transfer of domU’s across the network from one physical machine to the other. If this works, we could potentially swap out an entire computer without the hosted services being interrupted.
Raid Migration test:
- Made sure that both of the LV on both Dom0s are AOE exported and available on the other machines
- mdadm —stop the roti raid on pita, once its stopped, start it on zorro
- sync’d the roti xen config file and changed the xen config file from md0 to md1
- started up roti on zorro: xm create -c roti
We came up with the following steps that would be involved:
- need xen config on zorro that mirrors the roti config on pita
- roti0 needs to be vblade’d out so zorro can see it: vblade 0 0 lan /dev/mapper/vg_zorro0-roti0
- xm pause roti (takes the domu and writes the CPU and memory state on /var/lib/xen/save on pita)
- stop md0 on pita
- sync the image /var/lib/xen/save over to zorro
- reassemble the md device using the names of the devices on zorro
- xm wake
However, we realized that perhaps the xen-migrate(?) tools might provide a lot of these steps.
Failure scenarios¶
What happens if we loose an element of the array, either through loss of network communication to the second machine, or the second machine crashes, or the disk dies? Can we recover gracefully from this?
To test this we disconnected zorro from the LAN, in approximately 5-10 minutes pita noticed that the disk wasn’t responding and failed the device via mdadm. Although, there were no logs on pita anywhere that indicated a problem, roti was unresponsive when trying to perform disk access.
The AOE timeout seems to be ~3 minutes from the first hanging attempted use. I tried it by killing the vblade process on zorro at 22:03:06, and then immediately executing:
codetitle. as root@pita:
dd if=/dev/etherd/e0.1 bs=512 count=1 | hd
I found the virtual device on pita failed at 22:03:08:
codetitle. pita:/var/log/kern.log
Nov 10 22:06:08 pita kernel: Buffer I/O error on device etherd/e0.1, logical block 0
Nov 10 22:06:08 pita kernel: Buffer I/O error on device etherd/e0.1, logical block 1
Nov 10 22:06:08 pita kernel: Buffer I/O error on device etherd/e0.1, logical block 2
Nov 10 22:06:08 pita kernel: Buffer I/O error on device etherd/e0.1, logical block 3
Nov 10 22:06:08 pita kernel: aoe: aoeblk_make_request: device 0.1 is not up
Nov 10 22:06:08 pita kernel: Buffer I/O error on device etherd/e0.1, logical block 0
When we brought the network on Zorro back online, the device became available over AOE again and we could sync up the RAID array:
0 pita# mdadm --manage --remove /dev/mda /dev/etherd/e0.1 (fix this)
0 pita# mdadm --manage --add /dev/mda /dev/etherd/e0.1 (fix this)
Other failure scenarios we didn’t evaluate:
- What happens if there is a network outage or partition? Can we recover?
- What happens if a domU goes awol? is there anything you can do from within a domU to take down the parent dom0?
- What happens if a physical disk fails, but the parent machine continues functioning? Can we recover gracefully?
- What kind of I/O throughput can we expect over AoE? How does it compare with local disk throughput? (this kind of benchmarking might not be relevant if we’re using old hardware)
- Can we automatically resize disk space, memory, or CPU time allocated to a running DomU? What kind of flexibility does this give us?
Questions¶
Q. What would happen if two devices were exported to the network with the same shelf/slot pair? how would the clients react to that?
A. Need to determine this through experimentation.
Q. What if two clients were to try to mount the same AOE exported device at the same time?
A. Need to determine this through experimentation, but its likely not possible for multiple machines to access the same data in a safe manner with EXT, XFS, JFS and ReiserFS as these filesystems are designed to be used by a single host and its likely that filesystem corruption would result when multiple hosts try to mount the same block storage device. The reason this would happen is because the filesystem data is cached in RAM whenever possible to speed up the slower drive systems (the buffer cache, which is combined with the page cache in 2.6 kernels). This could be done with filesystems that are designed to be used by multiple hosts, such as cluter filesystems like GFS which make sure that the caches on all the participating systems are in sync with the filesystem and provides the locking to make sure the participating nodes access the filesystem properly to avoid corruption.
This opens up some really interesting possibilities. If we were to use something like GFS ontop of AOE, then multiple hosts could access the same storage at the same time, we could potentially bring up a second DomU of the same system while the first one is still running (although this presents other questions).
Q. How are the /dev/etherd devices created?
A. udev is responsible for maintaining the character devices in /dev/etherd, at any rate:
0 zorro:~# grep -C1 -ir etherd /etc/udev/rules.d/
/etc/udev/rules.d/udev.rules-# AOE character devices
/etc/udev/rules.d/udev.rules:SUBSYSTEM=="aoe", KERNEL=="discover", NAME="etherd/%k"
/etc/udev/rules.d/udev.rules:SUBSYSTEM=="aoe", KERNEL=="err", NAME="etherd/%k"
/etc/udev/rules.d/udev.rules:SUBSYSTEM=="aoe", KERNEL=="interfaces", NAME="etherd/%k"
/etc/udev/rules.d/udev.rules:SUBSYSTEM=="aoe", KERNEL=="revalidate", NAME="etherd/%k"
/etc/udev/rules.d/udev.rules-
0 zorro:~#
The eX.Y devices seem to be created by the kernel itself. The documentation on udev sayeth: “…if there are no matching rules, udev will create the device node with the default name supplied by the kernel.”
Q. Why isn’t aoe cleanly symmetric (i.e. why can’t an aoe exporter view its own exported devices as aoe devices? If it could, that would make for very clean configuration files, and improve the symmetry/transferability of domains.
A. It seems like vblade is a very simple tool, and intends to stay that way (see the file HACKING in the vblade source for the rationale). dkg resolved this asymmetry by creating a simple, automatable framework to manage persistent vblade-style AoE exports called vblade-persist. Its designed to bring up an AOE device for export on a server, and create a symlink on the server in the same location that the clients would see the device. The advantage of this symmetrical creation is that the /etc/xen/{roti,polori} config files are now generic, and the domUs can migrate freely across hosts, because AoE exporters now see the same device names as their clients. This makes clean migrations back and forth between Dom0s really easy.
Q. How do we get logical names for imported devices (ie. /dev/etherd/zorro0-roti0)?
A. Globally unique device names, dished out by a centralized udev daemon?! Or This could be as simple as a tree of symlinks, rsync’ed across the dom0’s, now that there’s the possibility of a symmetric set of device names. We would want to avoid a single-point of failure for this, and an rsync’ed tree implies a centralized master pushing out updates, which goes against the grain. Maybe a collaboratively authored DNS approach to a distributed set of bindings? (does avahi allow publication of txt records?)
If we could have a collaboratively-maintained, redundant set of files, we might as well use those files to host the xen configuration files directly (which could point to the numeric device IDs), as well as some sort of indication of which dom0 is hosting which domU.
Maybe a companion “aoeimport-persist” script would do the trick? But, we would need a good decentralized synchronization/publication mechanism for such a script.
Q. What about using kvblade instead of vblade?
A. We’ll need to experiment! (why would we want to do this, other than performance? It seems like a userspace process is safer, easier to control, easier to upgrade, and easier to audit than a kernel module.
Q. I read somewhere that LVM needs a couple tweaks made to its configuration to be useful in a AOE setup, “For one, it needs a line with
types = [ "aoe", 16 ]md_component_detection = 1A. dkg suspects that these steps are to allow a kernel to do LVM directly on top of a domU device. We never took that step; the aoe devices exported were extracted from an LVM, but they were imported raw as components to a RAID device. The RAID device itself didn’t have LVM on it, but even if it did, it probably would have been the domU’s kernel monitoring/managing that LVM, and from the domU’s point of view, the AoE devices are actually native SCSI devices.
Q. What about speed? Supposedly with a RAID-10 strip across 8 blades (four strip elements, each one a mirrored pair of drives) a sustainable read throughput of 23.58MB/s and a write throughput of 17.45MB/s was observed. “In general, you can estimate the throughput of a collection of EtherDrive blades easily by considering how many stripe elements there are. For RAID 10, there are half as many stripe elements as disks, because each disk is mirrored on another disk. For RAID 5, there effectively is one disk dedicated to parity data, leaving the rest of the disks as stripe elements. The expected read throughput is the number of stripe elements times 6MB/s. That means if you increase an 8-blade RAID-10 to a 18-blade RAID-10 you would expect to get more than twice the throughput.” Would be good to test with hdparm -tT to see throughput to see what the overhead waste is and throughput max we can achieve.
Q. What about corruption? On the network its not inconceivable that you could get out-of-order packets due to a faulty checksums, a bad NIC… could this result in silent data corruption? (google: tcp checksum hardware error, of particular note: portal.acm.org/citation.cfm?doid=347059..., “Even so, the highly non-random distribution of errors strongly suggests some applications should employ application-level checksums or equivalents.”) However, these problems are related to TCP checksum/CRC issues, and AOE ius done at layer 2 and TCP is not even involved, could there still be errors? It is a requirement of IEEE 802.3 that packets are not re-ordered, and that packets that are delivered are error free within the capabilities of the 32 bit checksum. It is not a requirement (of the connectionless mode of operation) that all packets are delivered so there must be a retransmission / error correction mechanism.

